





Just like oil was a natural resource powering the last industrial revolution, data is going to be the natural resource for this industrial revolution.
—Abhishek Mehta, CEO Tresata
An Agile Approach to Big Data in SAFe
![]() Note: This article is part of Extended SAFe Guidance, and represents official SAFe content that cannot be accessed directly from the Big Picture.
Note: This article is part of Extended SAFe Guidance, and represents official SAFe content that cannot be accessed directly from the Big Picture.
Data has become critically important across the entire enterprise. It influences business decisions, helps create better products, improves the way products are developed and drives operational efficiencies. This article describes the critical role data plays in the enterprise, the DataOps process to manage and deliver extensive volumes of data, and how to apply DataOps in SAFe.
Details
In the digital age, enterprises generate data at an astonishing rate. Each website click, turbine engine rotation, vehicle acceleration, and credit card transaction creates new information about products, consumers, and operating environments. The rapid acceleration of information has led to new practices for storing, managing, and serving massive data collections [1]. These Big Data practices deliver purpose-built data products to provide value across the entire enterprise, as Figure 1 illustrates.
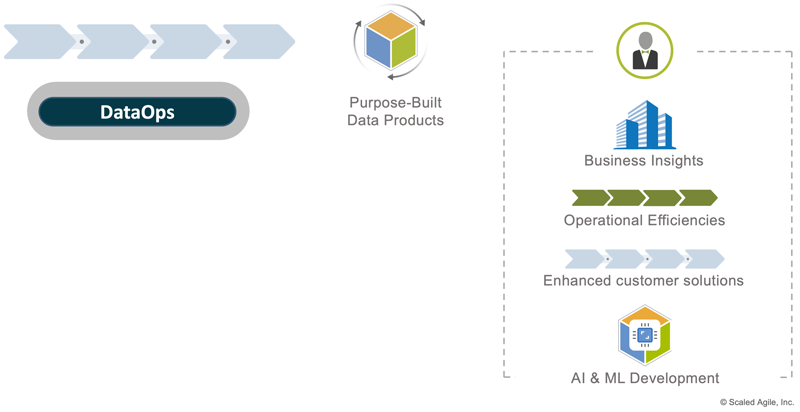
The Evolving Role of Big Data in the Enterprise
Data accumulation typically begins within organizational silos. A department collects information about its users and systems to enhance products, discover operational improvements, improve marketing and sales, etc. While this localized data is useful, aggregating large data sets across the entire organization provides exponentially more value than siloed data.
Exploiting Big Data for Competitive Advantage
Today, every enterprise uses data to improve their products, optimize operations, and better understand their customers and markets. Media and consumer product organizations use big data solutions to build predictive models for new products and services to anticipate customer demand. Manufacturing uses big data for predictive maintenance to anticipate failures. Retail businesses use big data solutions to improve customer experiences and effectively manage supply chains. Financial organizations use big data solutions to look for patterns in data that indicate potential fraud.
Supporting AI Initiatives
Organizations use AI and machine learning (ML) as a competitive advantage to provide better products to their customers, improve operational and development efficiencies, and provide insights that will enhance the business. As described in the Artificial Intelligence article, Artificial Intelligence initiatives focused on machine learning require large sets of rich data to train and validate models. Lack of sufficient data is a common reason for the failure of AI initiatives. To achieve AI goals, an organization must develop an enterprise-wide approach to collecting, managing, and delivering data collected across the organization along with external data to fill gaps.
Big Data Challenges
Collecting and aggregating this data poses challenges. The data community characterizes Big Data with the ‘3 Vs’:
- Volume – Data insights require a broad spectrum of data collected across the enterprise that can scale to hundreds of petabytes. As an example, Google processes 20 petabytes of web data each day. Big data solutions must collect, aggregate, and deliver massive volumes of data back to data consumers.
- Velocity – Data-driven decisions require the latest data. Velocity determines how quickly new data is received and refreshed from data sources. For example, a Boeing 737 engine generates 20 terabytes of information every hour. Big data solutions must decide which data to store and for what duration.
- Variety – Data originates in many forms across the organization. Traditional data from databases, spreadsheets, and text are easy to store and analyze. Unstructured data from video, images, and sensors presents new challenges. Big data solutions must address all types of data.
More recently, the data community has added Variability, Veracity, Value, Visibility, and other ‘Vs’ to characterize Big Data further and add to the challenges for storing, managing, and serving it.
Understand DataOps in the Enterprise
To address these challenges, organizations need a unifying approach. The Data Science community recognizes the stages organizations must go through in the Data Science Hierarchy of Needs [2] (Figure 2). At the foundation, Data Engineers (as part of System or Solution Arch-Eng on a Development Value Streams) design solutions that collect and manage data. This data and its storage are optimized for the application without concern for broader use.
As this data becomes more pertinent to the organization, Data Engineers (usually as part of a centralized data function) transform and aggregate the broader sets of application data into a data warehouse to make it available through data products such as marts, cubes, and views. Data Analysts and others use these read-only, purpose-fit data products for statistical analysis and visualizations. Data Scientists use them to develop and train models for AI and ML.
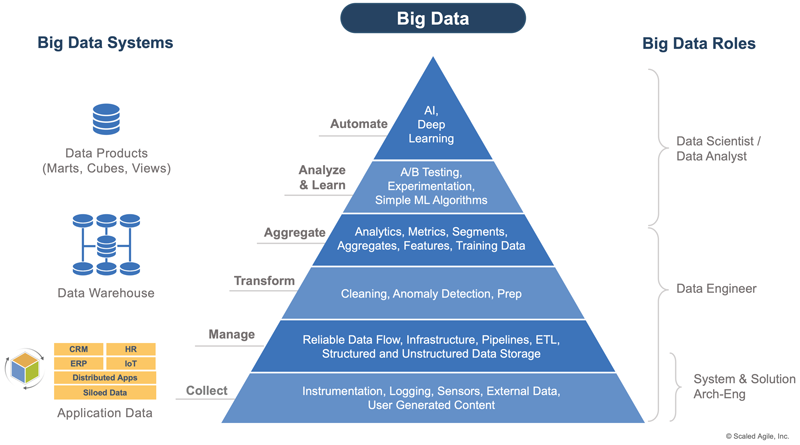
Individuals often play multiple roles. For example, a Data Analyst creating a dashboard who also has Data Engineering skills may go back into the data warehouse to transform and re-aggregate data for a new or updated view. However, an organization’s governance rules may restrict the ability of individuals to act in multiple parts of the pyramid. While most organizations take a centralized, Data Warehouse approach to data, distributed strategies like the Data Mesh are emerging, particularly for large organizations.
The DataOps Lifecycle
The Big Data practices above are performed continuously as part of the DataOps lifecycle model shown in Figure 3. DataOps is a collaborative data management activity across Agile teams, data practitioners, and enterprise stakeholders that leverages Lean-Agile and DevOps mindset, principles, and practices to deliver quality data products predictably and reliably.

The top-level flow shows how data moves from siloed application-specific data into data products offered to the various consumers. The bottom flow shows how data is consumed, governed, and used to enhance solutions that generate even more data into the pipeline. The remainder of this section describes each DataOps activity.
Collect Data – System and Solution Architect-Engineers, Agile teams, and system administrators build telemetry, logging, and monitoring to gather data on system and user behaviors. Product Management prioritizes this work. System Architect-Engineers ensure the solutions are easy to instrument and architected so the application data can be accessed externally, often through APIs. As data becomes more critical to the broader enterprise, work to collect better data and expose it through APIs may increase in priority and require capacity allocation (see Program Backlog) to ensure proper balance with other backlog items.
Aggregate & Transform – Data Engineers transform and aggregate data from across the enterprise into normalized forms optimized for efficient use by data consumers. A centralized data architecture ensures efficient storage and delivery of consistent data products across the enterprise. Data Engineers must balance the ‘Vs’ discussed earlier and determine which data to store, how long, tolerable access times, etc. They view data as a product and apply Design-Thinking and Built-in Quality. Personas and Journey Maps better connect them to their customer’s pains, gains, and user experience and determine how to offer better data products.
Deploy & Monitor – Data Engineers deploy data products from the data warehouse into various forms, including data marts, cubes, and views used by data consumers. Like other technology solutions, data solutions leverage Cloud technology and apply Continuous Delivery through a DevOps Pipeline designed for data. These practices quickly move data changes through development, Q/A, UAT, and production environments for feedback from consumers. These environments ensure dashboards, reports, models, and other artifacts dependent on the data content and formats can evolve with the data.
In the spirit of DevOps, monitoring occurs across all stages of the data CDP to detect anomalies in the data (row counts, data out of range) and data operations (unexpected timeouts) and send alerts to the data team.
Consume – Big Data consumers can be categorized into two groups, as shown in Figure 4. Analysts use data products to discover insights and create visualizations for specific data customers. Data Scientists and ML developers use them to develop and train models. Their customers (Data Customers in Figure 4) are enterprise-wide stakeholders seeking business insights for decision-making, improving operations, and enhancing customer solutions.
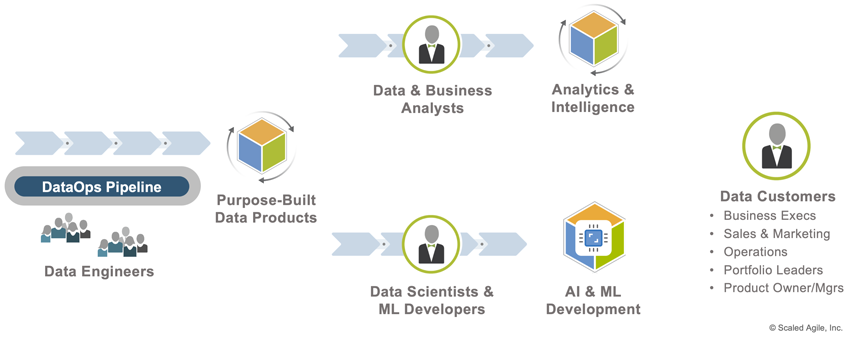
Different lines of business, product managers, AI developers, and others have unique data needs. To enable these individuals through a self-serve model, enterprises should invest in the tools, analytics packages, and resources to support ad hoc access for localized manipulation. This investment reduces the load on members of the centralized data team for reporting and other mundane tasks.
Govern – DataOps must enforce data privacy, confidentiality, residency, sharing, retention, and other legal requirements. The Big Data solution must ensure security through access controls, audits, and monitoring that detect intrusion and data breaches. Like other digital products, it must also provide fault tolerance and disaster recovery through a vendor or home-grown solutions.
Enhance Solutions – Portfolio and Agile Release Train (ART) leaders use data to enhance solutions to provide better customer value (better products) and business value (better data). Data analytics can reveal opportunities for new solution offerings and inform feature prioritization for existing solutions. Data gaps also show opportunities to enhance solutions to collect additional data.
Applying DataOps in SAFe
The previous sections describe the importance of a clear and compelling data strategy. This section describes additional guidance SAFe organizations can take to support their Big Data journey.
DataOps is a Portfolio Level Concern
Big Data is a portfolio-level concern as it requires vision, investment, and governance at the highest levels in the organization. While ARTs create the data, the value comes from data aggregation at the portfolio and enterprise levels. This requires strategic investment from the largest parts of the organization and a comprehensive approach that aligns each of the organization’s development value streams to the same DataOps practices to produce cohesive data sets used across the entire organization. Portfolio leaders use Lean Budgets to invest in Big Data infrastructure and DataOps practices to accomplish this. They also use Portfolio Epics and the Portfolio Kanban system to specify and prioritize the infrastructure, technologies, and data needs to support the organization.
Initially Centralize the Big Data Function
SAFe’s Principle #10, Organize Around Value, strives to optimize flow by ensuring teams and ARTs have all the skills necessary to deliver value. Unfortunately, most organizations are still growing their data engineering and science functions resulting in more demand than capacity for these skills. Initial centralization is often useful for early technology adoption to maximize available skills and create the DataOps infrastructure and practices. It also simplifies governance for privacy and security that would be virtually impossible to safeguard with a siloed approach.
Through customer-centric approaches described earlier, this centralized function can meet most of the organization’s data needs. Where additional support is needed, SAFe has a known pattern to provide additional services to other parts of the organization, the Shared Service, as shown in Figure 5.
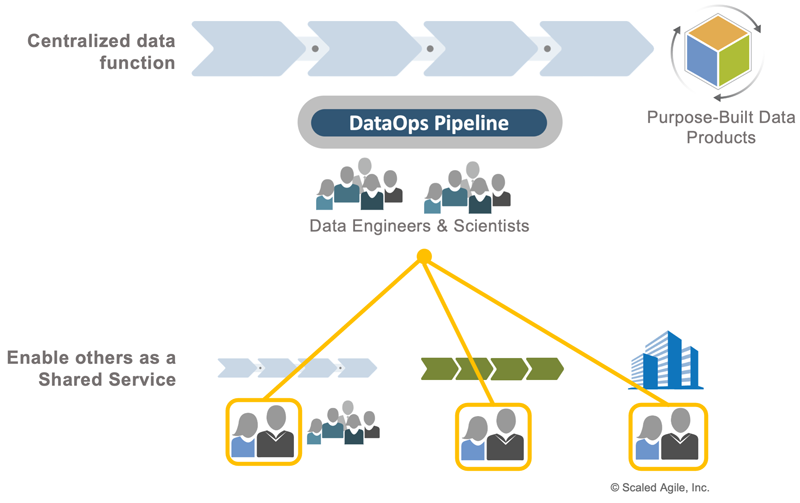
Over time, organizations will grow their data functions to support the broader enterprise and embed individuals in ARTs and Operational Value Streams. However, a ‘Big Data’ development value stream of Data Engineers providing aggregated enterprise data will likely exist for some time.
Grow Technical Talent
Data Engineering, Analysts, and AI/ML developer skills are in huge demand, and recruiting knowledgeable and skilled data specialists is a large challenge. Organizations must create a compelling and inspiring data and AI vision to attract and retain this talent. Data specialists want to learn and grow from other data specialists to keep pace with the rapidly evolving technologies and practices.
Applying DataOps to Build Better Solutions
Solutions are informed and augmented by data, and ARTs require Data Science and Data Engineering skills. As described earlier, the data functions can provide some resources to ARTs as a shared service. But they must balance that ART work with their primary responsibility to create and evolve the DataOps practices that includes data as a product to the enterprise. When supporting ARTs, they should act like an Enabling Team (see Agile Teams) to grow the technical data competence across the organization. In this capacity, they are not there to do the work but to teach others how to do it.
Learn More
[1] Kleppman, Martin, Designing Data-Intensive Applications, O’Reilly Media. 2017. [2] The data science pyramid. https://towardsdatascience.com/the-data-science-pyramid-8a018013c490
Last Update: 8 March 2022